Wir verwenden hier Messwerte einer Flammen OES (optische Emissions Spektroskopie) Messung von Kalzium. Eine Stammlösung wurde durch Einwaage von in 1% Salpetersäure eingewogen.
Es wurden 584 mg eingewogen und auf 100 mL verdünnt. Anschließend wurden mit einer Kolbenhubpipette Volumina von 50 µL bis 500 µL ( in 50 µL Schritten) entnommen und in 25 mL Kolben weiter verdünnt. Diese Standardreihe wurde dann vermessen. Die Daten sind ein einem Excel File “Ca_Kalibration.xlsx” im Sheet “Kalibration” gespeichert.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from IPython.display import Markdown
from uncertainties import ufloat, unumpyWir laden die Datei mittels Pandas
calibration = pd.read_excel(
"https://gitlab.tuwien.ac.at/cookbooks/data/analytical_chemistry/-/raw/main/Messunsicherheit/Ca_Kalibration.xlsx?inline=false",
sheet_name="Kalibration",
index_col=0,
)
calibrationWe plot the calibration
fig, ax = plt.subplots()
ax.plot(calibration["c"], calibration["I"], "x")
ax.set_xlabel("Ca Konzentration / (mg/L)")
ax.set_ylabel("I / counts")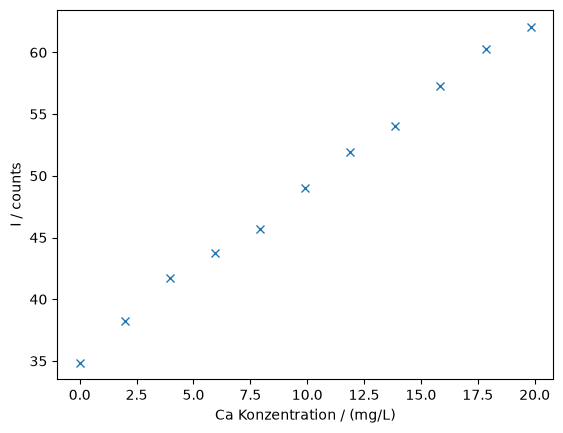
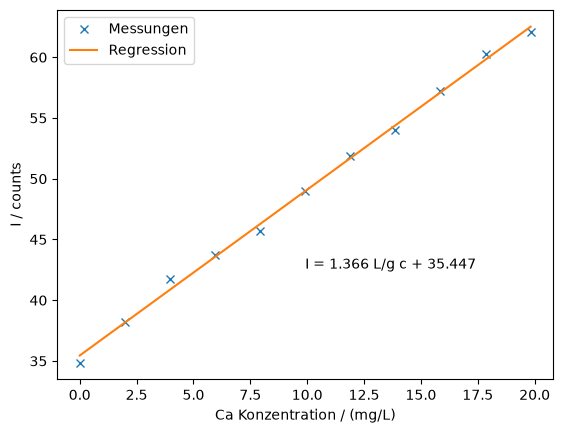
Wir könnten numpy.polyfit verwenden um diese Punkte mit einer Gerade zu fitten, aber zur Übung werden wir stattdessen die Gleichungen (2) und (3) in Python code gießen:
def linfit(x, y):
"""creates a least-squares fit of data pairs (x,y)"""
k = np.sum((x - np.mean(x)) * (y - np.mean(y))) / (np.sum((x - np.mean(x)) ** 2))
d = np.mean(y) - k * np.mean(x)
return k, dk, d = linfit(calibration["c"], calibration["I"])
fig, ax = plt.subplots()
ax.plot(calibration["c"], calibration["I"], "x", label="Messungen")
ax.plot(calibration["c"], k * calibration["c"] + d, label="Regression")
ax.set_xlabel("Ca Konzentration / (mg/L)")
ax.set_ylabel("I / counts")
ax.annotate(f"I = {k:.3f} L/g c + {d:.3f}", (0.5, 0.3), xycoords="axes fraction")
ax.legend()
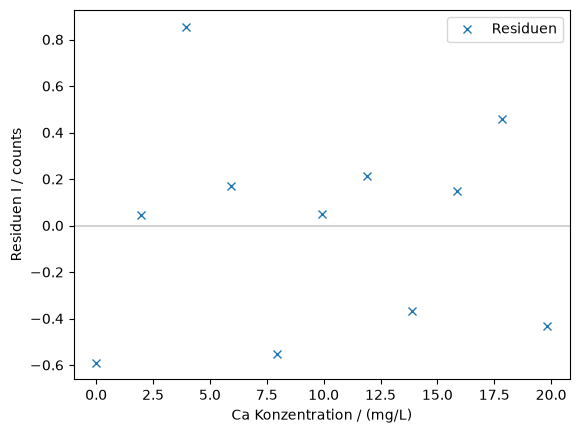
Bei einer Regression macht es auch immer Sinn die Residuen zu überprüfen. Sie würden Auskunft darüber geben, ob wir noch im linearen Bereich der Kalibration sind:
k, d = linfit(calibration["c"], calibration["I"])
fig, ax = plt.subplots()
ax.axhline(0, color="lightgrey")
ax.plot(
calibration["c"],
calibration["I"] - (k * calibration["c"] + d),
"x",
label="Residuen",
)
ax.set_xlabel("Ca Konzentration / (mg/L)")
ax.set_ylabel("Residuen I / counts")
ax.legend()
Nun verpacken wir auch die Formeln zu Berechnung des Standardfehlers von Steigung und Achsenabschnitt in eine Funktion
def s_linfit(x, y):
k, d = linfit(x, y)
sk = np.sqrt(
1 / (len(x) - 2) * np.sum((y - k * x - d) ** 2) / np.sum((x - np.mean(x)) ** 2)
)
sd = sk * np.sqrt(1 / len(x) * np.sum(x**2))
return sk, sdsk, sd = s_linfit(calibration["c"], calibration["I"])
fig, ax = plt.subplots()
ax.plot(calibration["c"], calibration["I"], "x", label="Messungen")
ax.plot(calibration["c"], k * calibration["c"] + d, label="Regression")
ax.fill_between(
calibration["c"],
(k - sk) * calibration["c"] + (d - sd),
(k + sk) * calibration["c"] + (d + sd),
color="lightblue",
)
ax.set_xlabel("Ca Konzentration / (mg/L)")
ax.set_ylabel("I / counts")
ax.annotate(
rf"I = ({k:.3f} $\pm$ {sk:.3f}) L/mg c + ({d:.2f} $\pm$ {sd:.2f})",
(0.3, 0.2),
xycoords="axes fraction",
)
ax.legend()
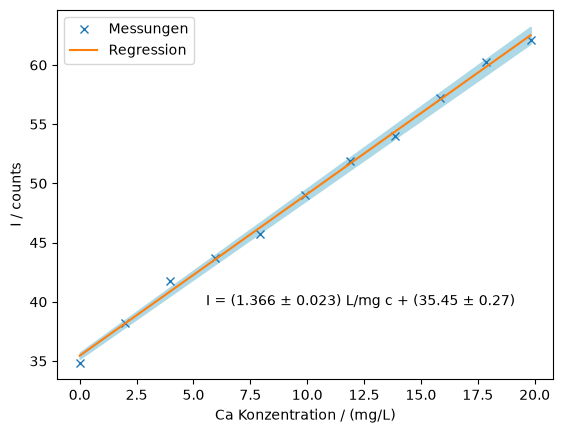
Die Ergebnisse für die Steigung und Achsenabschnitt sind daher:
Markdown(f"k=({k:.3f}±{sk:.3f}) L/mg\n d=({d:.2f}±{sd:.2f})")Fehler der Standards¶
Wir ignorieren bisher, dass die Herstellung der Standards auch fehlerbehaftet ist. Wir machen Fehler beim Einwägen, beim Pipettieren und beim Verdünnen von Lösungen. Es kann sein, dass diese Fehler zu Fehler in den Konzentrationen führen, die Vergleichbar mit dem Fehler durch die Messung sind. Das überprüfen wir nun mit Hilfe des uncertainties Pakets.
Zuerst berechnen wir die Konzentration der Stammlösung. Wir wiegen ein, rechnen dann in Mol Kalzium um. Da es sich dabei um chemische Formeln handelt, müssen wir dabei keine Messunsicherheit beachten. Schließlich verdünnen wir in einem 100 mL Kolben. Die Konzentration in Milligram pro Liter:
EW_CaNO34H2O = (
584
+ ufloat(0, np.sqrt(1 / 3) * (0.1 / 2), tag="Digitalisierung Waage")
+ ufloat(0, 0.1, tag="Repeatability Waage")
+ ufloat(0, 0.2, tag="Linearität Waage")
)
V_stamm = 100 + ufloat(0, 0.1 / 2 / 3, tag="Fehlerbereich Kolben")
M_Ca = 40.078 # g/mol
M_CaNO34H2O = 236.15 # g/mol
c0_Ca = EW_CaNO34H2O / M_CaNO34H2O * M_Ca / V_stamm * 1000
c0_Ca991.1307219987297+/-0.4167756653684643Nun pipettieren wir. Da wir dabei mehrere Werte gleich behandeln müssen, verwenden wir uarrays. Diese funktionieren wie numpy arrays haben aber für jeden Wert einen eigene Messunsicherheit. Die pipettierten Volumina sind in Mikrolitern, wir erhalten dann Ergebnisse in Milligram pro Liter.
pipette_volumen = unumpy.uarray(np.arange(0, 550, 50), [0] + [0.6] * 10) + ufloat(
0, 0.6, tag="systematische Fehler Pipette"
) * np.array([0] + [1] * 10)
c_stds = pipette_volumen / 1000 * c0_Ca / unumpy.uarray([25] * 11, [0.1 / 2 / 3] * 11)
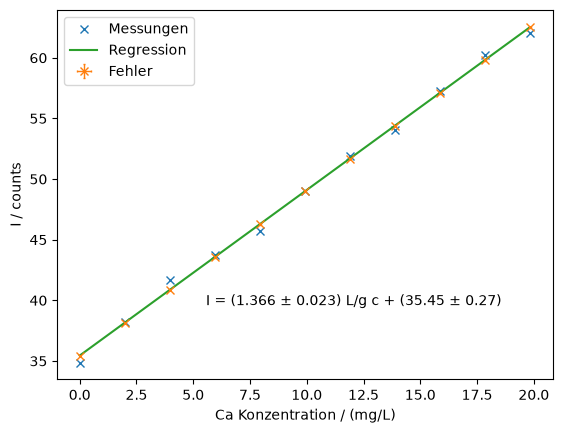
I_calc = k * c_stds + dSowohl für die Konzentrationen als auch für die daraus berechneten Intensitäten sind die Fehler klein, im Vergleich zu den Abweichungen der Messpunkte von der Regressiongerade. Es ist also anzunehmen, dass die Messunsicherheit durch die Schwankungen bei der OES Messung zu stande kommt. Wir machen uns das Leben daher einfach, und vernachlässigen die Beiträge der Probenherstellung zur Messunsicherheit von k und d.
pd.DataFrame(
{
"E(c)": unumpy.nominal_values(c_stds),
"s(c)": unumpy.std_devs(c_stds),
"E(I)": unumpy.nominal_values(I_calc),
"s(I)": unumpy.std_devs(I_calc),
}
)fig, ax = plt.subplots()
ax.plot(calibration["c"], calibration["I"], "x", label="Messungen")
ax.errorbar(
calibration["c"],
unumpy.nominal_values(I_calc),
marker="x",
linestyle="none",
xerr=unumpy.std_devs(c_stds),
capsize=1,
elinewidth=1,
yerr=unumpy.std_devs(I_calc),
label="Fehler",
)
ax.plot(calibration["c"], k * calibration["c"] + d, label="Regression")
ax.set_xlabel("Ca Konzentration / (mg/L)")
ax.set_ylabel("I / counts")
ax.annotate(
rf"I = ({k:.3f} $\pm$ {sk:.3f}) L/g c + ({d:.2f} $\pm$ {sd:.2f})",
(0.3, 0.2),
xycoords="axes fraction",
)
ax.legend()